Social Network Fragments- Chapter 7 from danah's thesis
[index][background][theory][implementation][presentations][contact]
[danah boyd][jeff
potter]
---
Social Network Fragments: A Self-Awareness Application
[This is only one chapter of Faceted Id/entity: Managing representation in a digital world, danah's Master's Thesis]
Since its conception, email has been the most popular use of the Internet and those online regularly engage in sending messages between one another (PEW Foundation 2001; Harlan 2001). It is through this forum that people keep in touch with loved ones, coworkers, and digital strangers. These interactions reveal characteristics about the individual, including their social networks. Yet, this data is often obfuscated by the system, making it difficult for people to easily grasp the patterns and social interactions that they engage in daily.
Motivated by the depth of information that email provides, Social Network Fragments is interested in explicitly revealing the social networks patterns that emerge in email, emphasizing the structural forms of one’s network and providing an interactive tool for people to reflect on their own habits. Understanding one’s social network is quite important for awareness and empowerment. People manage their social network as one aspect of managing the context of their lives. Thus, awareness of one’s digital network allows the individual to begin managing it online.
The purpose of this chapter is to detail the theoretical and practical components of Social Network Fragments, providing information as to its value in relation to self-awareness tools. As one of the applications chapters, it is intended to provide a detailed example of the process that we considered in developing a reflective awareness tool, as discussed in Chapter 4. By providing this detail, i intend to convey some of the challenges with which designers are faced.
As this project relies on the theories behind social networks, i begin by providing the relevant background material. Following this, i discuss the structural components of Social Network Fragments, including the system architecture and interface design. While discussing this tool, i critique our decisions and discuss the value of SNF as an awareness tool.
Background to social network analysis
Although personally constructed, one’s identity is impacted by one’s interaction with others. Many people have a variety of roles in an individual’s life and therefore they provide a variety of impact, ranging from the stranger on the bus to one’s best friend. Not only does the strength of an individual’s connection to others play a role, but also the context, the value and a wide variety of uncontrolled events. These people help comprise an individual’s social network, or the collection of people that the individual relies on for a variety of purposes. Although these people surround the individual, they may not all know, or even be aware of, one another. These holes in awareness or knowledge can be described as structural holes within an individual’s network, where the only relationship that one person has to another is through the ego whose network is being considered.
The structure of one’s social network conveys a great deal about an individual. How often does the individual maintain distinct relationships between groups of people?Do they have a few close friends or a large collection of less regular interactions? Are clusters within one’s network separated based on roles (i. e. work vs. family)?While most people manage their social network with minimal effort, it is difficult to gauge the structure of one’s digital network as the ego lacks the visceral experiences of shared space.
Considering related social network theory
Social network analysis is the study of the connections between people. These connections are valuable, because they are how people gather the different types of support that they need – emotional, economical, functional, etc. The types of connections – or ties – that an individual maintains varies, but they often include family, friends, colleagues, and lovers. In addition to a difference in type, ties vary in value or strength. Most commonly, social network theorists refer to two levels of ties – strong ties and weak ties, where a strong tie is able to offer a much greater magnitude of support than a weak tie. Although it may seem as though weak ties are not particularly valuable, Granovetter (1973) shows that there are distinct advantages to having weak ties, including increased information flow and social mobility. Since weak ties require less effort to maintain, it is in an individual’s best interest to maximize their weak ties, if they should want increased access to information.
In most cases, an individual has great control over the structure of their social network. Although there are times and places when societies are so small or so tightly integrated that everyone knew everyone else, for many people this is not their experience. More likely, individuals will develop associations with people who are not even aware of most of the people in an individual’s collection of acquaintances. These ties have a variety of purposes, and with each purpose, they have a difference in strength or importance. In some cases, a new tie might be neatly integrated in one’s previously formed cliques. In others, that tie will be kept completely separate or only introduced to a limited number of one’s ties. By controlling who knows who, an individual is able to explicitly manage their social network, providing connections as they see fit. When clusters of one’s network are kept separate, a series of holes in the network develop, such that the individual becomes the bridge between the clusters; this is known as structural holes.
Burt’s structural holes argument (1993) builds on Granovetter’s weak ties argument (1973). Burt argues that the advantages of weak ties are magnified for an anchor who is connected to different social clusters which have no other bridging connection. In other words, an individual who is the only person connecting one clique to another is advantaged. Not only does the individual gain from having access to a different set of information, they have the power to control what aspects of this information can be shared with the different social clusters to which they belong. Burt’s discussion of structural holes is heavily motivated by the flow of social capital and the competitive advantages of controlling information flow. In his scenario, maximizing and controlling the flow of information is essential and empowering, such that an individual seeks to acquire as much information as possible. Therefore, by being the bridge between multiple social clusters, an individual maximizes their ability to acquire and control information. Although Granovetter argues that all bridges must be weak ties (1973), Burt rejects the relevancy of tie strength, but emphasizes that weak ties in bridges are more advantageous.
While Burt suggests that being a bridge is purely advantageous, Krackhardt (1999) argues that it is also constraining for the individual who acts as the bridge. In his analysis of cliques, Krackhardt develops the idea of Simmelian ties, where an individual is Simmelian tied to another if they 1) have a strong tie to one another and 2) share at a strong tie to at least one other person in common (i. e. , they are part of a clique). Individuals who are members of a clique are constrained by the social norms of that clique such that Simmelian triadic ties are more constraining than simple, dyadic ties. Since each clique has a series of social norms by which its members are expected to follow, Krackhardt concludes that an individual who is a member of two separate cliques is constrained by the social norms of both groups, thereby needing to find the intersection of those norms in developing a socially acceptable face. Rather than seeing the bridging role as empowering, Krackhardt views it as a restrictive position, except in the case of private behaviors. In private scenarios, where only the particular clique and ego know about the behavior, the ego is advantaged by being the bridge, because they can act differently in different groups. Thus, if an individual seeks to maintain different social behaviors in different contexts, they become motivated to control social situations such that two cliques cannot converge, thereby guaranteeing private scenarios.
It is precisely these private scenarios that an individual desires when they want to maintain a multi-faceted individual identity. The individual produces their own identity information; therefore its initial flow comes from its creator and they control its initial recipients. Although trust and motivation plays a significant role in the passage of personal data, connections are also important. Regardless of trust and motivation, if information is passed to an individual with minimal ties, it is unlikely that the information will spread far. For this reason, one’s social network is a considered factor when valuable private information is being shared.
From an individual’s perspective, personal information is exceptionally valuable and therefore the individual wants to control its spread and content. The more valuable the information, the more closely the individual wants control. Should valuable information spread, it becomes gossip. Although individuals who are far removed are less likely to care to continue to spread the gossip, they are also less motivated to suppress its spread, as trust is less likely to override one’s desire to spread information. In order to account for the potential of gossip, it is in an individual’s best interest to minimize the ways in which it can spread. The most obvious mechanism is to only share information with ties who are close, trusted, and have no motivation to share the information. Another effective approach is to minimize access by developing and maintaining structural holes. Structural holes provide security by 1) limiting the percentage of your social network that can learn any bit of information from other members; 2) increasing the number of degrees necessary for information to jump from one clique of associations to another. Although Milgram (1967) shows that few degrees are necessary to connect any one individual to another, by assuming that non-ties are less likely to continue the spread of gossip, increasing the degrees of separation effectively limits the passage of information.
Since flow of identity information can be more easily managed in a network with holes, it is in an individual’s interest to maintain structural holes whenever possible, particularly when different cliques have different social norms. By being the only bridge between a set of work colleagues and a set of friends, an individual can portray two distinct social identities. Yet, once this faceting is started, it becomes more crucial that the structural holes are maintained. From Burt’s information flow perspective, an added bridge simply weakens the power of the original bridge. When segmented identity information is involved, an added bridge can be considerably destructive for the ego, depending on the potential impact of revealing unknown identity information. In both cases, an individual is empowered by being able to act as a sole bridge between two different social clusters, although for slightly different reasons.
Some individuals instinctively separate many of their social clusters, if for no other reason than to minimize restrictions and maximize privacy. Just as Krackhardt noticed, when social clusters are bridged and Simmelian ties are built, an individual’s behavior becomes constrained because they must follow the social norms of both communities simultaneously. Likewise, when an individual interacts with two cliques simultaneously, their behavior is effectively public, requiring a participation that will be appropriate for both forums. Although aggregated conformity might be expected for some individuals, Kilduff’s (1992) earlier work implies that the impact of such convergence might be highly dependent on one’s personal qualities, in particular their self-monitoring style. Because high self-monitors are quite likely to be influenced by their social surroundings, it follows that these individuals will be constrained when presented with combined social cliques with different norms. Conversely, as low self-monitors are less likely to adjust to social expectations, converging social clusters might not be so problematic.
It is important to note that converging social circles not only increase potential information flow and restrict acceptable behavior, but they also automatically increase identity information knowledge by making each cluster more aware of the individual’s network. Should a clique be associated with particular activities or interests, others are likely to assume participation or interest. Depending on the difference in values and interests between the two groups, this may not be problematic. For most people, homophily alleviates this concern, such that any clusters that an individual might have are likely to be very similar to the individual, and therefore likely to be similar to one another (McPherson, et. al. 2001). Problems are most likely to occur when an individual maintains a cluster of people whose similarities to them do not overlap with the similarities they have to another cluster. For example, converging one’s “anti-corporate/Marxist/activist” friends with one’s corporate colleagues not only constrains appropriate behavior, but makes each group aware of the individual’s involvement in the other.
Considering digital social networks
While most social networks literature is concerned with the physical world, Wellman, et. al. (1996) maintain that the same concepts are equally valid for those networks built and/or maintained in the digital world. While the theories remain the same, the ways in which people can manage and control their social networks are inherently affected by the strengths and weaknesses of the interaction paradigms possible when using digital tools. Additionally, the logged nature of one’s digital interactions provides a more complete record of one’s social network than is usually possible in the physical world. As such, researchers have shown that email offers great insight into an individual’s social network (Garton, et. al. 1999; Wellman & Hampton 1999; Rice 1994; Sproull & Kiesler 1991).
Analyzing email spools can provide a great deal of information about the ego. At the most basic level, one can derive to whom the ego speaks, how often, how much, and including which other people in the conversation. At a deeper level, one could derive what types of content are shared, what the differences in sending and receiving are, where the people are located and when references to real life events are made. These patterns are quite rich and can be used to say a lot about their authors. At the same time, they are not perfect – not all conversations happen online and some of the most frequent conversationalists may not be the closest ties in one’s network. While social network analysts should not want to use email as the sole source for understanding an individual’s behavior, this information is quite useful to the actual ego as they are quite able to separate out why some people are more prominent than others. As a result, the data still stands to convey rich information to the ego.
The social network of most people is quite large; manual studies of social networks have found that people average approximately 1500 ties of all different strengths (Killworth, et. al. 1990). Because of the ephemeral nature of people’s connections, there are even more ties documented in email; many digital connections are so tangential that offline researchers would not even consider them. The quantity of ties impacts the dimensionality of one’s network, because rarely do people maintain social networks where all members of their network are unaware of all others. Instead, there are many different types of ties between the different members of one’s network. By simply trying to imagine what the graph of such a system would be, it is easy to realize that this largely dimensional dataset is quite hard to comprehend. In response, Social Network Fragments seeks to make this information accessible through an interactive visualization.
Building Social Network Fragments
After considering the theoretical concepts introduced above, i recognized the value in making digital social networks accessible to people, for their awareness as well as management. So that they may consider the impact of their network on their identity, i wanted to create a system that would reveal the structure of their social network. To do so, i began collaborating with fellow Brown University alumnus, Jeff Potter. We both recognized the power of visualizing largely dimensional structural data through spring systems, as i had previously worked on Judith Donath’s Visual Who (Donath 1995) and he had worked a spring-based visualization tool emerging from the Memex project at Brown (Large Scale Design GISP 1998; Simpson 1995).
Using much of his original code, Jeff reworked the spring system to provide a layout algorithm for this largely dimensional dataset of email connections, based on a set of weighting systems that we determined were appropriate to numerically describe the relationship between any two individuals. Built on top of Jeff’s layout algorithm, Social Network Fragments consists of a visualization tool that allows users to interactively explore their data, accessing different clusters and see the data over time.
In this section, i begin by explaining the technology behind Social Network Fragments, including the input that users provide, the relational weighting we devised, the spring system that Jeff created, and the larger interface that we used to give users access to their data. Following the technological overview, i discuss the results by considering an example dataset provided by “Drew. ”
Data Input
When a subject offers data for us to visualize, they must first provide the information necessary for Jeff to analyze the messages for time/date/sender/receiver, evaluate the relations between people based on the relationships discussed in the next section, and pre-compute the layout. Ideally, such a system would recognize when two email addresses belong to the same individual or who belongs in which facets of the individual’s identity, but such is not currently the case. Thus, participants are asked to provide us with a set of four files that indicate the potential contexts and their colors, which email addresses should be associated with the subject, which email addresses are actually listservs, and a collapsing of all email addresses associated with any given individual. In the latter three files, subjects are encouraged to associate particular email addresses/listservs/people with particular contexts, which will affect the coloring in the system. The information that the subject provides helps the system more accurately determine the relationship between people, not just between email addresses.
Relational Dataset
At a fundamental level, our first priority was to determine the strength of the relationships between the different people in one’s network. Traditionally, people talk about strong ties and weak ties, but we are attempting to analyze one’s ties computationally, without any feedback from the user. Thus, we set about to categorize the different types of ties that exist in an email spool.
Knowledge ties. We assume that if A sends a message to B that A ‘knows’ B. (We do not assume that B knows A; we also do not assume that A knows B if the message went through a listserv. )
Awareness ties. We assume that if B receives a message from A that B is ‘aware’ of A.
Weak awareness ties. If B and C both receive a message from A, we assume that B and C are ‘weakly aware’ of each other.
List awareness ties. If B receives a message from A through a listserv, we assume that B is ‘listserv aware’ of A.
Trusted ties. If A sends a message to B and blind carbon copies (BCC’s) D, we assume that A ‘knows’ and ‘trusts’ D. We assume this because D has the ability to respond and reveal that A included people without B’s awareness.
We assume that most senders do not distinguish between the To and CC fields so we treat them identically (referred to as the To field from this point forward). We also assume that if no one is in the To field and everyone is BCC’ed that privacy is assumed and that there are no trusted ties. As this system only analyzes messages sent to the subject, we only know about the people that the subject BCCs and the people who BCC the subject. We do not know of anyone who might also have been BCC’ed on a message.
Example. Consider the following message:
From: Drew
To: Mike, Taylor
BCC: Morgan, Kerry
This produces a set of ties as follows:
Drew knows Mike; Drew knows Taylor; Drew knows & trusts Morgan; Drew knows & trusts Kerry
Mike is aware of Drew; Mike is loosely aware of Taylor
Taylor is aware of Drew; Taylor is loosely aware of Mike
Morgan is aware of Drew; Morgan is loosely aware of Mike and Taylor
Kerry is aware of Drew; Kerry is loosely aware of Mike and Taylor
We maintain bi-directional links in order to understand the strength of ties. Using this information, we construct a matrix of ties, including the quantity and type. Each type of tie is given a level of importance, such that trusted ties are more valuable than knowledge ties, which are more valuable than awareness ties, etc. Each value is additive, such that the more that two people converse with one another, the greater the value of the tie that connects them. While we found a set of values that seem to apply to many datasets, these constants can be altered depending on how much they make sense for a given subject. For example, if one consistently BCCs people for a reason other than privacy, it is foolish to overvalue trusted ties.
The relationship between any two people is given one numeric value, ranging from 0 (no connection) to 1 (most strongly connected). Time is divided into two-week intervals. For each time slice, the relational value is determined based on the additive value of each type of tie in relationship to its importance. It is done by time slice so that the subject can see as people begin connecting to one another. The weights are scaled across all people (except the ego/subject) and over all time such that each type of weight has a separate scaling. As the ego exists in a large percentage of the ties, the ego/subject’s weights are scaled separately just over time; otherwise, this would devalue all other weights to near zero. These weights also affect the visual properties of individuals. Color is determined based on the context in which the individual knows both the subject and the other people in the network. Personal contexts override listserv contexts, which override email address contexts. For example, consider the following message, where Drew is the subject and is writing from his WORK email address:
From: Drew
To: Mike, Taylor, Morgan
Assume that the following people have been overridden with particular contexts:
Mike: COLLEGE
Morgan: FAMILY
In such an example, the following weights would be used to determine the coloring:
Drew: 1 COLLEGE context from an awareness tie; 1 FAMILY context from an awareness tie; 1 WORK context from an awareness tie (because Taylor is not overridden)
Mike: 1 COLLEGE context from an awareness tie; 1 FAMILY context from a weak-aware tie; 1 WORK context from a weak-aware tie
Taylor: 1 WORK context from an awareness tie; 1 FAMILY context from a weak-aware tie; 1 COLLEGE context from a weak-aware tie
Morgan: 1 FAMILY context from an awareness tie; 1 COLLEGE context from a weak-aware tie; 1 WORK context from a weak-aware tie
Spring System
In order to determine how an individual is geographically positioned with respect to the others in the system, Jeff implemented a simple spring system that reacts to a combination of forces that pull and repel different anchors from one another. First, there is a gravity force that pulls all nodes towards the center of the graphical world. Without the gravity force, island nodes would expand infinitely. There is also a repulsion force that makes all nodes repel from nodes that are within a certain distance, which also means that things do not actually expand infinitely. These two forces result in a system that only considers repulsion and gravity forces, such that without any other forces, the system would settle into an evenly spaced circular ball of data. The constants that determine these two forces are dependent on the size of the dataset, and are tweaked to magnify the structural features.
In addition to the default repulsion, each pair of nodes/people is assigned an attraction spring based on the weight of the ties between the two people. When two people are not tied, the repulsion spring is the only force operating; when people are strongly tied, the attraction force outweighs the repulsion force. Although the attraction forces are directly mapped to the strength of the tie, the repulsion constant is altered to be appropriate for the given dataset. As clusters of nodes form, their aggregated repulsion force further repels unrelated nodes.
At the start of Jeff’s pre-compute system, all nodes are randomly positioned in the geographical world. The system begins stepping through a series of iterations in order to find a layout in which most nodes are relatively settled. For each iteration, the nodes assess the system of forces that are impacting them (gravity, local repulsion, connected node attraction) and determine what an ideal geographic position would be given those forces. As moving to that ideal position assumes that all other nodes would be staying in the same position, each node only moves a fraction of the distance in the direction of its ideal position. This procedure is then repeated. Over time, nodes settle into a position where the distance that they must move is so minimal that they begin to visually shake, because they are moving back and forth between two pixels, trying to find a position between the two. At this point, the system has reached a settled phase.
|
|
Figure 7-1. This image is derived using our example data provided by Drew. In the image, we see all of Drew’s nodes in a position where they’ve reached a settled layout. The result resembles a galaxy, with various solar systems. Due to the initial random layout and the general centrifugal gravity, this algorithm frequently pulls the most highly connected clusters towards the center. |

While the settling algorithm results in beautiful clustering of related nodes, it is still compressing n-dimensional data into a 2. 5 [1] dimensional space. As a result, some nodes are geographically close to one another, even though they are unrelated. Such scenarios occur due to a fundamental restriction in graphing highly dimensional data on a plane.
|
|
Figure 7-2. By focusing on one cluster in Drew’s network, we can see the graph layout problem. In order to explain the problem, consider the inset. While E is completely unrelated to D and C, they are just as geographically close as the two nodes with which E has strong ties. This occurs because both A and C are also strongly tied to D, B, and E. Additionally, the length of ties fails to accurate represent distance, as the length of the tie between E and A is much shorter than between A and D even though they represent the same strength. In Drew’s network, the problem is even more convoluted, as the dimensionality of connected nodes is greater. Such complication makes it difficult to determine who is really closer to whom. |
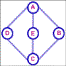

This graph theory problem is inevitably a weakness of a system such as ours, which collapses n-dimensional data into a 2. 5D space. While we considered doing a 3D version of this, we both agreed that the confusion that 3D adds does not outweigh the advantages of an extra graphical dimension, particularly since we are dealing with >500 dimensions of data.
Another dimensional weakness of our current spring system implementation is that it does not take into account time in determining layout. While we present the data to the user over slices of time, the layout algorithm assumes that all items will be shown simultaneously. By using two dimensions of space and one dimension of time in laying out the graphs, we would dramatically improve the visibility of the data.
User interface
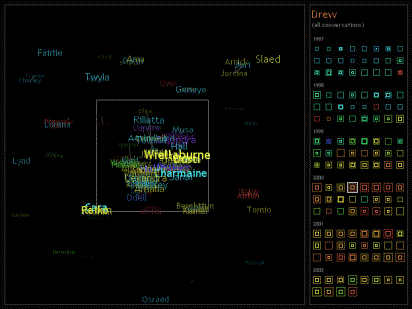
The interface for Social Network Fragments is comprised of two frames, the network frame and the history frame. The temporal length of email interactions is divided into two-week periods such that every slice of the animation shows two weeks worth of data. When the system is initialized, the network frame shows the data from the first time slice and the history frame highlights the time slice that is currently being observed. The subject is not shown in the network frame, but their overriding data is the default view for the history frame. Consider Figure 7-3 for a view of the entire interface.
|
|
Figure 7-3. While earlier figures showed segments of the network view, this image shows the complete interface. Drew’s data is obfuscated, but the structure remains in tact. The left frame is the network frame while the right is the history frame. The history frame has the current time slice highlighted and the box in the network frame shows the region in which the user is currently zooming. The colors represent the contexts in which Drew knows the various people, where yellow refers to her social friends, teal to her college mates, and red to her research colleagues. |
Positioning. The aforementioned layout springs helps determine the positioning of the nodes within the network frame. Because integrating the settling into the system is too computationally intensive, we pre-calculate the position of each node. As i mentioned before, this presents a problem, such that people are not laid out with each time slice in consideration. This creates the appearance of unrelated people near each other without connections because their strong connection appears during a different time slice. Thus, a preferred mechanism would be to consider laying out each time slice separately. Yet, this also poses an interface problem, as it would mean that individual nodes would jump from one section of the screen to another, making it difficult for the user to see the continuity. To deal with this, one would want to show the traces of movement, so that the user appears to be moving from one cluster to another over time. For the layout to be more meaningful, time needs to be directly integrated into the geographical positioning.
Connections. Given a minimum weight for a time slice, a line is drawn between two people to recognize that they are related to one another. This allows the viewer to know if two people are truly connected or nearby due to a function of the layout mechanism. These connections are more clearly visible in Figure 7-2.
Coloring. The size and brightness of an individual relates to the magnitude of the person’s weighted connections at a given time slice. Color is predetermined based on the context and weight of all relationships at that time. The ego’s color is also a general weighting of the various connections for each time slice.
Zooming. By selecting a region of the network with a mouse, the system slowly zooms into that area, holds, and zooms out. Further zooming or a mouse down will stop the system from zooming out. A square is drawn around the desired region so that the user can see what they are aiming towards. Our zooming mechanism can be confusing for users because there is no easy way to pull out of a given zoom or shift over without waiting for the system to start zooming out.
Time. As time marches progresses, people emerge and become connected with other people. In the current system, time marches at a speed of one day per second. There is a minimum weight for an individual to be shown in a given time slice, although they are phased in during the time slice before and phased out in the one following the slice when their weight drops below the minimum. The history panel serves as both a system clock as well as a temporal overview of the entire dataset. Each square region represents a time slice of two weeks, the default time period, where the oldest areas are at the top of the screen. By clicking on a square, the current time is adjusted to the starting time of that time slice.
Time overviews. Inside each time slice in the history panel are potentially three smaller squares. The outer square represents the weight for all awareness ties; the middle square represents the weight for all knowledge ties; and the inner square represents the weight for all trust ties. While these squares are relative to the scaled weights, the meaningful value is in their comparison; no square is drawn if there is a zero weight.
History view. The history panel shows an overview of the entire system. By default, the ego is shown, where all of the time overviews are the ego’s relation to others. Yet, by clicking on the name of someone in the network panel, the history panel reflects the historical interactions between the ego and the selected user, as shown in Figure 7-4.
|
Figure 7-4. When a name is selected in the network panel, the person’s name is highlighted and the history panel changes to reflect the relationship between the person and the ego. Thus, in this image, we see all of the connections between Charles and Drew, noting that they only starting conversely a few months into 1999 and that their interactions were pretty consistent over time. |

The interaction paradigm that we used in designing this required only a mouse, as it was designed for exhibition. Such a paradigm limited the types of interactions people could have and our zooming mechanism was not intuitive. For personal use, we also added additional features such as a find box and key commands for immediate zoom and filters. Such interactions would be useful for those engaging with this interface.
Discussion
The awareness that people using Social Network Fragments seek regards their social network structure. Thus, the most compelling aspect of SNF is viewing the clusters that form and trying to understand the meaning that they have to the user. Clusters develop because of common ties; by looking at the clusters, the subject is able to have an image by which they can tell their story and the story of various encounters. Just like a photo album snapshot, these images are often more meaningful to the subject than the researcher. Consider one of the clusters that appear in Drew’s network.
|
|
Figure 7-5. By zooming into a region in Drew’s network, we can see a collection of clustered people. Aside from its structural beauty, this cluster represents a collection of people that are important to Drew. Using this image, Drew is able to tell a story about who these people are and why their clusters are meaningful. |


Drew first noticed the colors. She had assigned purple to represent her activist friends, green to be associated with her collegiate context, and yellow as a default color for friends. Although it was not specifically assigned, blues result from people who Drews knows from both the collegiate and activist contexts of her life.
Drew is actively involved in both the collegiate and national organizations associated with her particular activist community. The cluster containing Dubaku consists of people who are associated with the national organization, some of whom know Drew simply through the organizational context, while others also know her through one of her collegiate contexts. Hall, the primary outreach coordinator is also in regular communication with one of the local productions that Drew directs at her college, primarily through the Drew’s co-organizer, Wiellaburne. Although Drew is in charge of the collegiate organization, her primarily relationship with the people in this cluster is through the college. Some of these people are also connected to other college mates of Drew’s, and the unseen network branches on the left lead to other facets of Drew’s college life. Another noticeable feature of this data is that, at this time slice, Drew is more heavily involved with the national organizers than with the local members.
While this anecdote may seem meaningless to the reader, the recognition of these relationships were quite powerful for Drew. The self-portrait provided a visual mechanism for her to recollect historical events and activities and to notice aspects of her communication that she had not previously realized. When i showed Drew the bridge between Hall and Wiellaburne, her initial response was shock, because she did not realize that she and Wiellaburne were the only people who communicated with Hall. After pausing, she explained that this actually made a lot of sense, as she could not recall anyone else who knew Hall. This type of reflection is one of the ways in which the ego can use these images to be aware of their own connections and that of those around them.
We created six personal portraits and each person who saw their images were able to share stories about particular clusters or connections. The data was not surprising, as much as it was revealing. By being forced to explicitly consider and reflect on the relationships that are taken for granted, people recognized that their interactions could be graphed and that reading this graph is meaningful.
Critique
In providing subjects with a tool to grasp the structure of their relationships, SNF provides a level of awareness about one’s social network that is not normally available. Although this data is at the fingertips of all digital social beings, people rarely consider it. While pieces such as Viégas’ PostHistory (2001) provide a compelling look at the statistical data of one’s email interaction, SNF provides a much more qualitative perspective. Yet, this approach has significant weaknesses.
Evaluating ties. Although we have given serious consideration to the mechanisms by which we evaluate the value of a relationship, the impact of our numerical representation must be considered, as it only provides one perspective on the relationships described. Nowhere is this more obvious than in the evaluation of the BCC ties. While we have assigned them to indicate trust, that is not a universal use of BCC. Likewise, just because someone receives an immense quantity of messages from another does not mean that they are closer ties, yet our system assumes so.
Actual awareness. Even when discussing the notion of awareness, we assume that the person’s browser reveals all of the CCed people, yet this is not true; many people do not even know that the message that they received including many other recipients. Thus, assuming loose awareness can be inaccurate.
Layout. While the clustering is quite stunning and appealing, the design portrays misleading information as an artifact of the layout algorithm. As i discussed earlier, the collapsing of highly dimensional data into a 2. 5D space presents a visual image that is quite misleading; many geographically close people are not actually strongly connected; it is an artifact of the algorithm.
The major weakness in systems such as SNF stem from our attempts to convey qualitative data in a manner that gives resounding impressions. By using computational evaluations to produce qualitative ideas, we are faced with both the problems of evaluating the data and conveying the impressions. In this way, the problems that we face in visualizing data in SNF resemble many of the problems that Hyun and i only began to address in Loom2 (boyd, et. al. 2002). As impressions are so crucial for giving people awareness, the weaknesses of SNF indicate why this problem is so challenging.
Yet, while the weaknesses are many, the images still provide a valuable
insight into an individual’s social network structure. Seeing the structure
of one’s interactions for the first time is quite thought provoking, as
it provides a level of insight and awareness to one’s interactions that
are normally inaccessible. This level of awareness not only provides a
system for telling stories, but also for reflecting on one’s behaviors
and intentions through a compelling interface. By addressing this need,
Social Network Fragments would be quite a valuable tool if we redesigned
certain aspects of it to address the underlying flaws.
---
[1] 2.5D uses both X and Y coordinates as well as applying layers. Thus, the information appears to be laid out along a third dimension that cannot be navigated.