
Talking In Circles:
A Spatially-Grounded Multimodal Chat Environment
Roy Rodenstein, Judith S. Donath
Sociable Media Group
MIT Media Lab
20 Ames Street
Cambridge, MA 02142
{
royrod
,
judith
}@media.mit.edu
http://www.media.mit.edu/~royrod/projects/TIC
ABSTRACT
This paper presents Talking in Circles, a multimodal chat environment which emphasizes spatial grounding to support natural group interaction behaviors. Participants communicate primarily by speech and are represented as colored circles in a two-dimensional space. Behaviors such as subgroup conversations and social navigation are supported through circle mobility as mediated by the environment and the crowd and distance-based spatialization of the audio. The circles serve as platforms for the display of presence and activity: graphics are synchronized to participants’ speech to aid in speech-source identification and participants can sketch in their circle, allowing a pictorial and gestural channel to complement the audio. The system is implemented using the internet’s multicast backbone. We note design challenges inherent in creating a rich environment for computer-mediated communication, including network infrastructure and human perceptual issues, and how we have approached them as our system has evolved.
Keywords
: Computer-mediated communication, chat, multimodal interaction, audioconferencing, multicast, social navigation, drawing, affective communicationINTRODUCTION
Communication is one of the primary applications of computing. Electronic mail has become ubiquitous in certain sectors, with synchronous computer-mediated-communication surging in the last decade through networking improvements and critical mass of the online population. Chat, whether purely textual or accompanied by graphics, has ridden the growth of the World-Wide Web to become a popular medium for social interaction. Traditional chat environments, however, are limited by the physical and expressive bounds of typing as input for synchronous communication.
Talking in Circles aims to support rich, natural interaction by creating an environment for computer-mediated social interaction in which speech is the primary communication channel and graphics convey important expressive and proxemic information. The environment is a two-dimensional space within which participants are represented in abstract form, as circles of various colors. This representation allows a degree of individual differentiation and serves as a physical marker of the participant’s location within the chat space.
The audio in Talking in Circles, generally speech, is multicast from each participant to all others, and the play volume of each remote user’s audio is computed based on distance from the local user. Thus, while all participants have an equivalent shared view of the space, the mixed audio is rendered subjectively for each participant based on their location. This property gives rise to behaviors such as approaching those one is interested in conversing with, forming conversational subgroups of several users located near each other, and mingling by moving around within the space, listening for topics of interest and moving to join particular groups.
The circles serve as indicators of presence and as cues about membership and activity in various conversations. They are also used as platforms for graphical display. As participants speak, a brighter inner circle appears whose radius changes according to the energy of their speech. This feedback is synchronized with the speech and updated continuously, providing an indication of each participant’s activity. As importantly, this display of the rhythm of each speaker’s audio lets the user connect the voice heard to the circle representing the corresponding speaker. The screen shot in Figure 1 shows these graphical features at one instant in time in a Talking in Circles chat session.
Figure 1: Three conversations in a Talking in Circles chat session.
Although speech is a very natural form of communication and allows a great range of expression, it is largely a serial and transitory modality [Schmandt 98]. As a complement, Talking in Circles lets participants draw in their respective circles. This channel allows for a wide range of uses, from pictorial, such as diagrams or faces denoting expressions, to gestural, such as pointing, to entirely abstract, such as doodling along to music. Drawing can also be combined with motion of one’s circle, for example to indicate for which participant one intends a certain drawing or speech sequence. Drawings fade away with time to permit a constant pictorial dialogue without a burdensome interface of drawing controls. To facilitate use of the pictorial channel we also provide a user-customizable set of clickable icons for common expressions such as confusion, amusement and surprise, visible along the right edge of Figure 1.
In the following section we review previous systems relevant to the design of Talking in Circles. We then focus on the interaction design of our system and analyze it in the context of relevant studies. Next we describe the implementation, noting our responses to technical challenges. We conclude by discussing directions for future work in this area.
RELEVANT SYSTEMS
Many systems have been used to research computer mediation of audible communication between people. In general these are geared toward computer-supported collaborative work or focus on particular modalities. Sellen, for example, has studied speech patterns in several forms of videoconferencing [Sellen 92]. Isaacs and Tang compared face-to-face and videoconferencing interaction on several factors, such as the ability to have side conversations and to point [Isaacs 93]. We briefly discuss a few previous systems, informed by these studies, relevant to the design of Talking in Circles.
Thunderwire is an audio-only media space studied over several months [Hindus 96]. Although the system did not foster much work-related communication, it was very successful as a sociable medium based on such criteria as informality and spontaneity of interactions. Interesting norms evolved as a result of the lack of visual feedback to deal with finding out who was listening on the system and to indicate lack of desire to converse at particular times.
FreeWalk took the opposite tack, placing participants in a three-dimensional environment with video for each participant mapped onto a flat surface [Nakanishi 96]. This system also succeeded in fostering certain social behaviors, such as following a participant from afar. Audio was faded based on distance, though not based on the direction participants faced, leading to difficulty in speaker identification in some cases.
Sun’s Kansas system also uses videoconferencing within small windows and a distance threshold for audio [Kansas]. Geared toward distance learning, it employs a screen-sharing approach to complement videoconferencing with various applications.
In the graphical realm, systems such as The Palace [Palace] and Comic Chat [Kurlander 96] use text-based communication enhanced with changeable displays of avatars for participants. Previous work in our group includes ChatCircles, a text-based two-dimensional chat space where participants are represented as circles [Viegas 99]. ChatCircles displays participants’ typed messages on their circle, whose expansion thus signals activity. The text is not visible to participants beyond a threshold distance from the sender.
A common thread among these systems is the desire to support natural conversational qualities such as awareness of participants, the ability to point, and behaviors for turn-taking and controlling the floor. We now discuss the design of Talking in Circles, analyzing our system in light of these aims.

Figure 2: Screenshot from the point of view of Al, the blue circle. Andy is within Al’s hearing range, while Sandy is now outside it.
SOCIAL INTERACTION DESIGN
A first issue we dealt with was helping users map the voices they hear to the circles representing the respective participants. We use a bright inner circle displayed inside their darker circle to represent the instantaneous energy of the speech from a particular participant. Figure 1 shows that Sandy and Al are speaking, with their inner circles’ size showing how loud their speech was at that instant. Thus, natural pauses in conversation, which leave only particular circles showing speech activity, make this cognitive matching problem much simpler. Distance-based spatialization, discussed below, also helps, as speech from circles farther from the user’s circle sounds fainter. Finally, identity cues such as learning a participant’s voice and name also resolve matchings.
We conducted an informal test of the graphical feedback provided by the dynamically-changing bright inner circle. Six subjects were shown two circles with non-identifying names, equidistant from their own circle and at equal volume. The two test circles each played a different RealAudio news stream, and we asked participants about their experience in trying to match the two speakers they heard to the circles. Although this scenario is challenging, with constantly overlapping speech and no individuating cues for the circles, all subjects reported satisfaction with their ability to match speech to its corresponding circle. Though simultaneous speech was at first confusing, the subjects mentioned that the occurrence of short natural pauses in the speech soon made the matching apparent, as only one voice was heard and only one circle was bright. A similar situation happened when one speaker said something loud causing one bright inner circle to grow visibly larger than the other. In general, the subjects said the speech-synchronized updating of the bright inner circle’s radius let them notice matching rhythms in the speech.
Spatialization
Given the system’s capabilities, as described in the introduction, several behaviors are supported directly while others arise out of a combination of modalities. The most salient behavior is position as an indication of interest and membership in a conversation. As Milgram notes, rings are a naturally-emerging configuration of people engaged around a common activity [Milgram 77]. In Talking in Circles, as in face-to-face situations, standing close to someone permits one to hear them clearly, while also reducing distraction from other sources farther away. This natural tendency toward physical alignment resulting from distance-based spatialization in our system, besides being a functional conversational feature and serving to a limited extent the role of gaze, has peripheral benefits. It allows other participants to view the formation of groups or crowds around a particular discussion, letting them gauge trends in participants’ interest and advising them of conversations that are potentially interesting. As in real life, a gathering can continue to draw people as newcomers wonder what the fuss is about.
An additional important benefit of this crowd motion is simply the aliveness with which it imbues the space. Whyte remarks on the fact that the biggest draw for people is other people, and notes the popularity of people-watching as a form of triangulation— simply stated, a stimulus source which can be observed by multiple members of the population, potentially giving rise to conversation between strangers. The grounding in a 2D space may also bring in features such as traveling conversations, where conversants move across a space to find a comfortable spot along the perimeter [Whyte 88]. As in real life, it is possible, with some effort, to be near a particular speaker but attend to another, or to stand between two groups and attend to both conversations.
This physical grounding, along with the audio spatializations, also make applicable behaviors related to the so-called ‘cocktail-party effect’ [Cherry 53]. Though audio from those one is closest to is heard most clearly, nearby conversation can be heard more softly if within a distance threshold. This helps a user concentrate primarily on the conversation group they have joined while preserving the possibility of ‘overhearing,’ such that the mention of a name or keyword of interest can still be noticed. Thus, social mingling is fostered, as participants can move between subgroup conversations as their interest changes or move to an unoccupied physical space and start their own conversation.
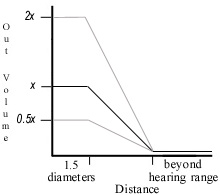
Figure 3: Output volume as a function of distance from a speaker, for input volume x (black line), 0.5x and 2x.
In order to allow clear audio for participants in a conversation, no audio fading is done within a distance of 1.5 diameters from the center of each speaker’s circle. This allows participants located next to or very close to each other to hear the full volume of speakers’ speech, while we still perform fading for circles in conversations farther away. Figure 3 plots the shape of the audio-fading function to show how output volume varies by distance from a speaker. The function remains the same but is parameterized by the instantaneous input volume, as shown by the upper and lower lines in the figure. This modification to the spatial rules of our environment preserves the positive qualities of audio fading but helps members of a conversation hear each other clearly; our focus on spatial grounding is always rooted in fostering a sociable space.
The distance threshold for audio to be heard also serves multiple functions. Naturally, it aids performance optimization by obviating the need for audio playback for those clients beyond the threshold. The major benefit, however, is letting the user know that they cannot hear someone, as activity by those beyond the hearing range is rendered as a hollow circle. For example, screen shots of a Talking in Circles chat from the screen of participant Al, the blue circle, shows he has moved from a conversation with Andy and Helen in Figure 1 to one with Josh and Yef in Figure 2. The hollow orange inner circle shows that Al is now beyond the hearing range of Sandy. Since the hollow circle still indicates speech, however, a participant can still note a flurry of activity even if they cannot hear it, and can move closer to see what the discussion is about if they so desire. The audio threshold is symmetric, such that if user X is too far to hear user Y, Y is also too far to hear X. This feature lets a user easily find a spot where they cannot be heard by a certain group, by noting when their inner circles appear hollow. Thus, as in a real cocktail party, one can move to the side to have a semi-private conversation, although this privacy relies only on social rules and is not enforced or guaranteed by the system. These interaction possibilities address some shortcomings of video-mediated conversation, such as the lack of a "negotiated mutual distance" and of a sense of others’ perception of one’s voice [Sellen 92].
One group of Media Lab sponsors which viewed the system suggested that, in their corporate setting, they would be interested in private breakout rooms for a couple of participants each, as well as a larger full-group meeting room. Although Talking in Circles can easily be adapted to support such a mode, our focus on a purely social space makes relying on existing social behaviors more interesting to us than technical enforcement of boundaries. A related concern is that of rudeness or other undesirable behavior by participants. Once again, the system’s rich interaction design can support emergent social mores that help sort things out; just as people can move closer to conversations or people they are interested in, they can move away from conversations which become uninteresting or people who show hostility.
Beyond these pragmatic features of spatializations, other potential sociable applications exist. For example, with a low audio distance threshold the popular children’s game of "telephone" is playable, in which a large circle is formed by all attendees and a short phrase or story is whispered from person to person around the circle, becoming increasingly distorted, until it gets back to the originator and the starting and ending phrases are revealed to everyone. Though not always desirable, yelling across the room to get someone’s attention or to say something to everyone present is also possible.
Circle Motion
Overlap of participants’ representations is a problem some graphical chat systems, such as The Palace, have faced. Avatars partially obscuring each other, whether accidentally or purposely, can arouse strong responses from those caught underneath. Visibility, as well as bodily integrity of one’s representation, are important social factors in graphical chats. Talking in Circles deals with both of these factors by not permitting overlap, simultaneously preserving visibility of participants’ presence and of their drawing space.
A circle’s motion is stopped by the system before it enters another circle’s space. In this situation, a participant can drag the pointer inside the circle blocking their path and their own circle follows around at the outer edge of the circle that is in the way, which provides the feel of highly responsive orbiting. Thus, at close quarters, participants still preserve their personal space and can move around in a manner which provides a certain physical interaction with other participants, an attempt at enhancing the feeling of being in a crowd the system provides. Swift motion across large areas is still immediate, as obstructing the participant with all circles along the way to the new location would make for a cumbersome interface. As always, our aim is to leverage spatial grounding with a primary focus on social interaction design, hence our differing policy for motion at close quarters versus over greater distances.
Drawing and Gesture
One major benefit of audioconferencing, of course, is that it frees the hands from being tied to a keyboard. This freedom can be employed to run Talking in Circles on a keyboardless tablet, as mentioned earlier, or on a wearable computer. Unlike traditional chat systems we need not display large amounts of text, which takes up a lot of screen real estate, resulting in great freedom in maximizing the potential usage of the space and the graphical area marked off by each circle.
Circles in and of themselves show presence, an indication of who may be listening, which users of the audio-only Thunderwire found tricky to determine [Hindus 96]. Since the circles’ interior space is used only momentarily during speaking, this space can be used for drawing on the circle. Drawing strokes appear in bright white, visible even over the graphical feedback during speaking, and fade away in 30 seconds. Although this precludes permanent records, our aim is closer to letting people at a cocktail party use a napkin to sketch on. This refresh rate keeps the drawing space available, which is important if drawing is to be useful for gesturing. Although the space on one’s circle is limited, it is large enough for diagrams, bits of handwriting, and so on.
Drawing faces is a natural tendency, and it is particularly inviting given the circular shape of the user’s representation. The circle’s space is enough to permit much more than simple emoticons, and even drawing-unskilled users immediately took to writing short phrases and drawing faces. Combined with moving one’s circle, drawing a face can be targeted at a particular user both by drawing the face as facing in that user’s direction and by moving toward that user with the face showing on one’s circle. Coordinating motion with drawing has been popular in some cases, such as drawing a face with the tongue sticking out and moving quickly up and down next to the intended viewer, enhancing the facial expression with bodily motion.
Shared drawing is also useful for showing explanatory diagrams [Tang 91], which Isaacs and Tang note as a user-requested capability in their study [Isaacs 93], for certain kinds of pointing, and potentially for other meta-conversational behaviors such as back channels. These uses are important in creating a social space since studies of telephone conversations have found reduced spontaneity and increased social distance compared to face-to-face discussions [Rutter 89]. Employing drawing, confusion can be indicated not just by explicit voicing but by a question mark or other self-styled expression on one’s circle. As the system is used in various environments we are very interested in studying the development of novel drawing conventions and gestures for conveying various data. Floor control can also be effected by drawing an exclamation point upon hearing something surprising, or simply by shaking one’s circle a bit to indicate one has something to say. Again, although voice by itself is useful in these tasks to some extent, both audio-only and videoconferencing studies have found complex tasks such as floor control to be less effective than can be done in face-to-face communication. Thus, the complementary combination of voice, circle motion and drawing is aimed at overcoming some of these limitations.
In order to make the pictorial modality more accessible, we also provide a set of clickable icons that display drawings in the user’s circle, similar to the availability of preset graphics in The Palace. As shown in figure 2, the system currently includes a question mark and exclamation point, as well as expressions indicating happiness, humor, surprise and sadness. The drawings available on the icon bar are standard graphics files editable in any graphics editor, and the drawings the system includes can be removed or modified or new ones added simply by putting them in the Talking in Circles directory. The ready access to showing these iconic drawings on one’s circle and the ability to customize this set of drawings makes the pictorial channel more available than requiring the user to draw everything from scratch each time. The icon-bar drawings can be clicked on in sequence and are updated immediately, which allows for higher-level expressive sequences such as pictorially sticking one’s tongue out while making a humorous remark, followed by displaying the winking face and then the smiling face.
Lastly, drawing can of course be used strictly for doodling, whether out of boredom or to accompany music one is listening to, and for other purely aesthetic ends. Individuals’ use of their drawing space —whether they draw constantly or rarely, make abstract doodles, draw faces or words— may provide others a sense of the person’s identity Besides being an expressive channel, these behaviors serve as another form of triangulation, giving participants a spectacle to watch and gather around..
SYSTEM IMPLEMENTATION
The requirements for Talking in Circles focused on full-duplex audioconferencing between a substantial number of simultaneous users, where we defined substantial as between a dozen and 20. Even experimentally, we were interested in low-latency audio, as lag is known to be detrimental to the use of speech for social interaction, for example leading to greater formality [O’Conaill 93]. However, we were also interested in creating a system that could have as wide a user base as possible, important given our focus on social applications as well as to facilitate wider, extended study of the system’s use. This meant that we could not use proprietary broadband networks or high-speed LAN’s, as high-bandwidth systems have typically done.
We initially looked at designing for the internet as a whole, but this of course proved intractable. Even highly compressed, multi-second-buffered protocols such as RealAudio occasionally suffer from unpredictable network delays and must pause to rebuffer [Progressive]. Given our primary requirement for low lag, buffering was not an option, especially buffering on the order of seconds. Next we looked into Java solutions, both third-party and Sun’s early-access JavaSound API implementation [JavaSound]. Again, latency was the major obstacle, with measured end-to-end lag varying between two and three seconds for machines on the same high-speed LAN subnet. Although further development of JavaSound is sure to improve on this performance, we were unsure our goal of 0.3-second maximum latency could be met, particularly after including the rest of our system design.
Finally, we settled on adapting RAT, the Robust Audio Tool, an open-source audioconferencing tool from University College, London [UCL 98]. RAT uses the MBONE, the internet’s multicast backbone, for network transport [Savetz 96]. This fulfilled several of our goals. Although not as general a solution as writing for the internet at large, the MBONE is an open network and many universities are members. The major benefit the MBONE provides is that it was designed specifically for multicast. Rather than using a client-server architecture, which would have introduced an extra network transmission and processing for all packets, or a strictly peer-to-peer architecture, where transmission by the local client would require O(n) passes, where n is the number of participants, multicast makes the cost of transmission constant. Each client sends its audio only once, and it is then multicast to the other clients.
After modifying RAT to better support conferencing between multiple participants with various characteristics (x/y location, circle color, instantaneous audio energy, and so on) we found that the system fulfills our requirements. End-to-end lag has been measured at approximately 0.3 seconds, considerable but not detrimental unless participants can also hear each other directly [Krauss 67]. This performance was measured with unoptimized compilation under Windows NT 4. Performance improves with optimized compilation as well as under Windows 98 and Linux. In addition, the bottleneck in our current implementation is screen redraw, as discussed below, and accordingly we have noticed no substantial performance degradation when varying the number of users from one to eleven.
Although the audio code, including compression/ decompression and MBONE transport, is written in C, we wrote the user interaction portion in Java using the Java Native Interface in Sun’s Java 2 platform. Signing on to the system is done via a Java logon screen, and the input user name and chosen circle color are transmitted from Java to C, as are the circle’s location and strokes drawn on the circle. This data is multicast to the other participants using the same networking system as audio, so updates to circles’ position and drawing also happen with very little latency, although audio transmission is given priority.
Conversely, audio is received in the C modules and instantaneous energy computed for each remote participant’s audio on a per-packet basis. The energy is passed to Java, where background noise suppression and logarithmic normalization are performed to map the energy value onto the circle’s area. This results in graphical display of energy as a bright inner circle updated many times per second, as shown in figures 1 and 2. Playback volume of the audio is computed based on distance and, beyond a threshold, no sound is audible and the bright inner circle is displayed only as a hollow outline, as explained in figure 2. Although this graphical feedback is synchronized with audio playback, the high update rate results in screen redraw being the major bottleneck to system responsiveness. Screen redraw cost is relatively constant, however, and scalability has been adequate, as discussed above.
To summarize, each participant multicasts the following:
The interface is rendered from these features, and all participants’ displays share:
Finally, the local user’s relative location produces a subjective rendering of:
As RAT exists for several platforms, we have ported our changes to it to both Solaris and Linux. A difference in the workings of the Java Native Interface between Windows and Solaris/Linux remains to be resolved before Talking in Circles can be released for these operating systems. Maintaining the user interface in Java, however, has kept the system highly extensible, making the addition of capabilities such as drawing straightforward.
As mentioned, audio is given priority over drawing and location transmission. Each compressed audio stream requires a few kilobytes/second, depending on the compression format, compared to bytes/second for motion and drawing data. Given their relative bandwidth requirements, this prioritization does not generally cause any noticeable delay in transmission of the subordinate data.
Another optimization is our use of a form of Bresenham’s line algorithm for interpolation between points when a user draws. Given the high processor requirements of receiving and mixing multiple audio streams in real time as well as drawing synchronized graphics several times per second, Java’s mouse updating during dragging is quite sparse. Without interpolating between points, gaps appear when trying to draw which are visually jarring enough to destroy users’ feeling of drawing responsiveness, making drawing frustrating. This fast line algorithm restores the immediate feel of drawing and in general does not result in overly rectilinear drawing, a possible pitfall when joining highly spaced points.
CONCLUSIONS AND FUTURE DIRECTIONS
In designing Talking in Circles, we have strived for a rich medium for communication along dimensions including interactivity, that is, responsiveness, and expressiveness, or "multiplicity of cues, language variety, and the ability to infuse personal feelings and emotions into the communication" [Chalfonte 91]. While speech has been found to have reduced cognitive load compared to text generation [Kroll 78] and to be the key medium for collaborative problem-solving [Chapanis 75], as Chalfonte et al found text still has certain advantages. For structured data, such as URL’s, text is clearly superior to speech due to its permanence and precision. Further, text-based CMC supports threading more so than face-to-face communication [McDaniel 96], which can add fluidity and variety to conversation. Though the ability to draw and do limited handwriting in Talking in Circles can help in some cases, textual communication can nevertheless add to the set of useful channels at users’ disposal. We are also interested in exploring the usefulness of non-explicit communication through affective channels [Picard 97]. Unobtrusive sensing of temperature or skin conductivity, displayed graphically, might add a valuable human element to individuals’ representation.
Another view of the system is that of Benford et al’s schema for shared spaces. According to their criteria Talking in Circles is of medium transportation and artificiality, and of extremely high spatiality, supporting on-going activity, peripheral awareness, navigation and chance encounters, usability through natural metaphors, and a shared frame of reference [Benford 96]. We are interested in extending the system’s spatiality even further, such as by providing greater persistence and meaning to the space, that is, increasing its sense of place [Harrison 96]. This might be done by modifying the background of different chat sessions or by permitting wear on the space. We are also interested in extending our framework for participants’ navigation along architectural notions studied by Whyte, such as the social significance of central and peripheral areas in plazas or the flow of people at street corners [Whyte 88].
A related area for future work is in preserving history in an audio chat. ChatCircles has used spatially-useful history mechanisms based on conversation groups at various points during a chat [Viegas 99], but parsing and browsing of sound remains a major challenge. Braided audio is one potentially advantageous recent approach [Schmandt 98].
A suggestion we have heard often is making the audio fully spatialized, rather than based only on distance. This could certainly add to the system’s spatiality, but we first intend to observe how straightforward users’ mapping of spatialized audio is onto the flat 2D surface Talking in Circles presents. Given visual components of auditory scene analysis, greater emphasis on gaze direction as explored by Donath might also be of great benefit [Donath 95].
REFERENCES
[Benford 96]
Benford, Steve, Brown, Chris, Reynard, Gail and Greenhalgh, Chris. Shared Spaces: Transportation, Artificiality and Spatiality. In Proceedings of CSCW ’96, ACM, November 1996.
[Chalfonte 91]
Chalfonte, Barbara, Fish, Robert S., Kraut, Robert E. Expressive Richness: A Comparison of Speech and Text As Media for Revision. In Proceedings of CHI ’91, ACM, May 1991.
[Chapanis 75]
Chapanis, Alphonse. Interactive Human Communication. Scientific American. 232, 1975, pp. 36-42.
[Cherry 53]
Cherry, E. C. Some experiments on the recognition of speech with one and with two ears. Journal of the Acoustical Society of America, Volume 25, 975-979, 1953.
[Donath 95]
Donath, J. The Illustrated Conversation. Multimedia Tools and Applications. Vol. 1, March 1995.
[Harrison 96]
Harrison, Steve and Dourish, Paul. Re-Place-ing Space: The Roles of Place and Space in Collaborative Systems. In Proceedings of CSCW ’96, ACM, November 1996.
[Hindus 96]
Hindus, Debby, Ackerman, Mark S., Mainwaring, Scott and Starr, Brian. Thunderwire: A Field Study of an Audio-Only Media Space. In Proceedings of CSCW ’96, ACM, November 1996.
[Isaacs 93]
Isaacs, Ellen A. and Tang, John C. What Video Can and Can’t Do for Collaboration: a Case Study. In Proceedings of Multimedia ’93, ACM, August 1993.
[JavaSound]
Sun Microsystems, Inc. Java Sound API. http://java.sun.com/products/java-media/ sound/index.html
[Kansas]
Sun Microsystems, Inc. Kansas. http://research.sun.com/research/ics/kansas.html
[Krauss 67]
Krauss, R. M. and Bricker, P.D. Effects of transmission delay and access delay on the efficiency of verbal communication. Journal of the Acoustic Society of America. 41, 1967, pp. 286-292.
[Kroll 78]
Kroll, B.M. Cognitive egocentrism and the problem of audience awareness in written discourse. Research in the Teaching of English. 12, 1978, pp. 269-281.
[Kurlander 96]
David Kurlander, Tim Skelly and David Salesin. Comic Chat. In
[McDaniel 96]
McDaniel, Susan E., Olson, Gary M. and Magee, Joseph C. Identifying and Analyzing Multiple Threads in Computer-Mediated and Face-to-Face Conversations. In Proceedings of CSCW ’96, ACM, November 1996.
[Milgram 77]
Milgram, Stanley. The Individual in a Social World. Reading, MA: Addison-Wesley, 1977.
[Nakanishi 96]
Nakanishi, Hideyuki, Yoshida, Chikara, Nishimura, Toshikazu and Ishida, Toru. FreeWalk: Supporting Casual Meetings in a Network. In Proceedings of CSCW ’96, ACM, November 1996.
[O’Conaill 93]
O’Conaill, B.,Whittaker, S. and Wilbur, S. Conversations Over Video Conferences: An Evaluation fo the Spoken Aspects of Video-Mediated Communication. Human-Computer Interaction. 8, 1993, pp. 389-428.
[Palace]
The Palace, Inc. The Palace.
[Picard 97]
Picard, Rosalind. Affective Computing. Cambridge, MA: MIT Press, 1997.
[Progressive]
Progressive Networks, Inc., http://www.real.com
[Rutter 89]
Rutter, D.R. The role of cuelessness in social interaction: An examination of teaching by telephone. In Roger, D. and P. Bull (ed.), Conversation: An Interdisciplinary Perspective. Multilingual Matters, 1989.
[Savetz 96]
Savetz, Kevin, Randall, Neill and Lepage, Yves. MBONE: Multicasting Tomorrow’s Internet. IDG, April 1996.
[Schmandt 98]
Schmandt, Chris. Audio Hallway: a Virtual Acoustic Environment for Browsing. In Proceedings of UIST ’98, San Francisco, CA: ACM, November 1998.
[Sellen 92]
Sellen, Abigail J. Speech Patterns In Video-Mediated Conversations. In Proceedings of CHI ’92, ACM, May 1992.
[Tang 91]
Tang, J.C. Findings from observational studies of collaborative work. International Journal of Man-Machine Studies. 34(2), 1991, pp. 143-160.
[UCL 98]
University College London. Robust Audio Tool. http://www-mice.cs.ucl.ac.uk/multimedia/software/rat
[Viegas 99]
Fernanda B. Viegas and Judith S. Donath. ChatCircles. To appear in Proceedings of CHI ’99, ACM.
[Whyte 88]
Whyte, William H. City: Rediscovering the Center. NY: Doubleday, 1988